Reimplementing MLU's OurMIPS Assembler
By Heinrich Preiser • 6 minutes read •
This is an old article which I never got around to publish.
At our University, we have a dialect of the MIPS32 Assembler which we use to learn processor architecture concepts. It mostly adds of a few magic instructions for inputting numbers and outputting text; this allows students to see results and get some hands-on experience and better understanding of the CPU.
There are two implementations of the compiler and emulator:
- Philosonline, which runs on WebAssembly and thus has decent performance. However, there is a bug in the implementation of the
bgt(Branch-Greater-Than) instruction, which can cause it to jump wrongly due to an integer over- or underflow. - Yapjoma, which runs on pure Javascript, in other words, it’s horrendously slow and not able to run some of the more complex exercises in a reasonable time frame.
Since I also wanted to learn the Assembler better, I built my own Compiler and Emulator for OurMIPS (Git Repo, “temporary” website). I decided to call my implementation ourMIPS or OurMIPSSharp.
Phase 1: Figuring out a Language Specification
I realized pretty quickly that I actually had no idea how OurMIPS works, and that even the two existing implementations are incompatible with each other. For example, Macros use different keywords and have different constraints in philos and yapjoma. I worked with the philos documentation as a starting point, and tested what worked and what didn’t in each system through trial and error. I managed to support multiple dialects based on toggleable language features, and by default my implementation understands both philos and yapjoma syntax. I also tried to allow for some degree of strictness to ensure compliant code, but I didn’t want to waste my time reverse-engineering edge cases. This means that you can’t use OurMIPSSharp to check the syntax according to either of the two other implementations.
I also kept bytecode compatibility with Philosonline, and yapjoma where possible.
Phase 2: Implementing a compiler
This was fairly straightforward, since the assembler supports no complex expressions. Initially, the source code is parsed with a Tokenizer into a list of Tokens which retain information such as their token type, string content and location in the source file.
Then, the actual compiler takes four iterations:
- Find Macros. At this stage, the compiler looks for macro keywords and creates a lookup table with their indices in the token list.
- Expand Macros. At this stage, the compiler looks for usages of macros, and inlines the macro body at the corresponding location, substituting macro parameters as needed. It doesn’t modify the original token list but rather creates a new one which omits the macro declarations.
- Find Labels. At this stage, the compiler looks for label declarations in the expanded token list, and creates a lookup table with their indices.
- Generate Bytecode. Now, the compiler processes each instruction in the expanded token list and generates a 32-bit unsigned integer encoding the instruction along with its parameters. For jumping offsets, the label lookup table from iteration 3 is used.
I made sure to produce error messages based on the tokens’ source code position as well as frequently check for unexpected tokens. To check the correctness of the bytecode, I compiled the same program in philos and ourMIPSSharp, until the bytecode was identical. Well, I always put 0s in irrelevant places but philos hides those places with * characters.
Now, I omitted two common aspects of compilers: Abstract Syntax Trees and Optimizations. This is mostly because the syntax was so simple that any AST more complex than a list of tokens was overkill. As this is intended as a tool for learning how the assembler works, it also would be undesirable to apply any changes to the program, since that would likely make it very confusing for students.
Phase 3: Implementing an emulator
This also went smoothly. I just had to implement decoding of the uints and a handful of classes to hold the contents of the Registers as well as a Dictionary/HashMap-backed RAM.
To check that my emulator was working, I wrote a program that utilized all of the available instructions and verbosely printed their results. I generated a bunch of random RAM values and initialized the RAM in philos as well as the RAM in ourMIPSSharp to the preset. Then I ran both programs and compared the results. To my initial confusion, they were not identical! A handful of calls to bgt behaved differently in philos than in ourMIPSSharp. It turns out, that the bug wasn’t in my emulator but in philos!
To make sure that my emulator kept working, I wrote a unit test to automatically re-run the test program and check the result.
Phase 4: Adding a GUI
This is the harder part. And by far the most time consuming!
I built the UI using AvaloniaUI, a free cross-platform XAML-based framework for building pixel-perfect GUIs in C#. I didn’t know Avalonia beforehand, but had some experience with UWP, so I felt at home easily. Except that everything in Avalonia is much better than in UWP! It has all the good sides of Microsoft’s .NET and XAML-Based frameworks, like WPF, but improves on the weaknesses such as age and lack of cross-platform support. It even has some experimental WASM-Support, but that’s not quite production-ready: You loose both the usual benefits of web technologies (namely the DOM-related optimizations and accessibility) and the performance of desktop apps, since .NET doesn’t have proper multi-threading in WASM.
Besides Avalonia, I also used the ReactiveUI library for creating responsive MVVM ViewModels. This took some getting used to, as I had never tried reactive programming before.
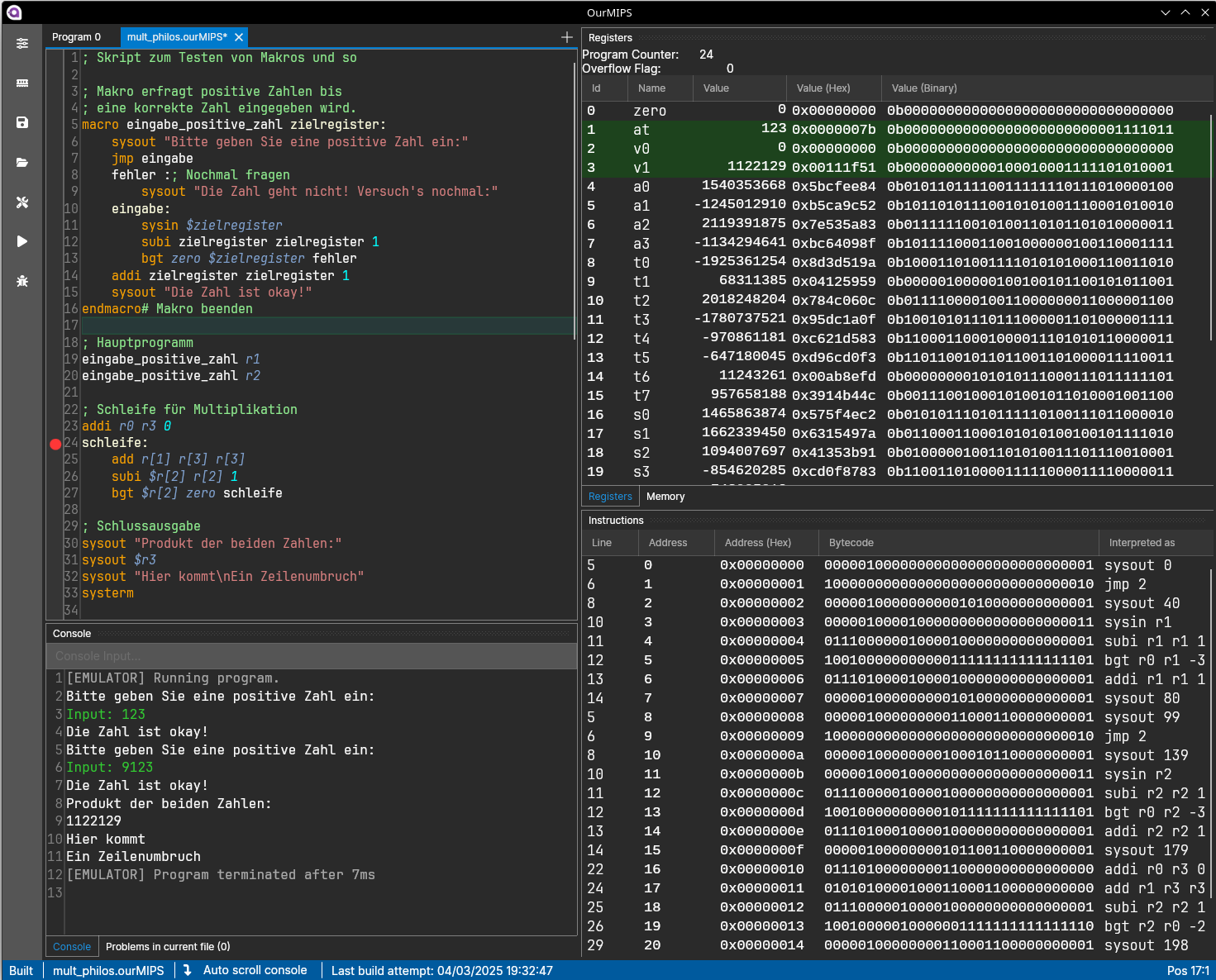
All in all, it took quite some time to get a stable UI. But I’m relatively happy with how it turned out. On the screenshot, you can see the main screen. You can resize and rearrange the different windows to fit your needs. And there’s a debugger as well, along with an automatic debug break on runtime errors.
Wrapping up
So, that was a little project I did last year. I initially wanted to add more features like autocompletion or in-editor documentation. But life got busy and I eventually stopped development. I hope this was interesting to read :)